I wanted to share a recent project that we worked on at Diamond Edge. I can say that this was the single most challenging and complex integration architecture we have ever had to design, all while keeping in mind performance. The complexity was driven by the requirements, and the limitations of the systems we were interfacing with. Let me explain some of the requirements and how we solved them architecturally.
Requirements
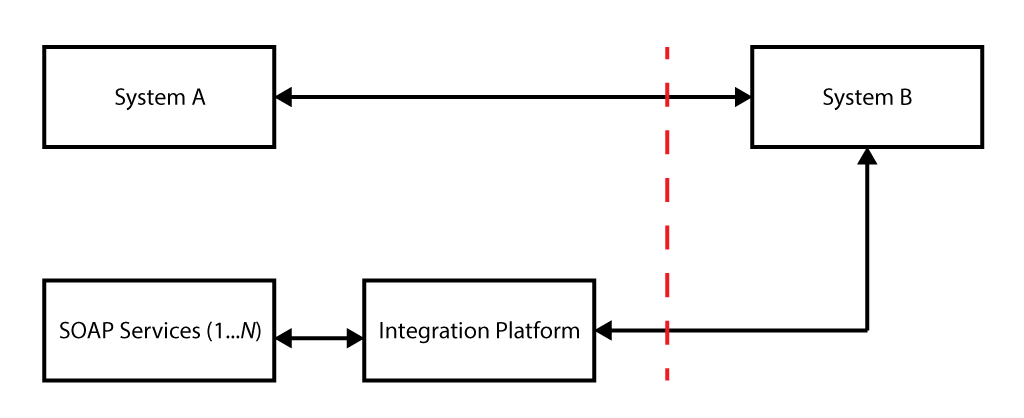
System A is the front end system written in .NET. It collects data from a page based form, calls some SOAP Services and collects the data and sends it to System B which is a REST Service using JSON. Most of the data is sent through in key value pairs where some of the values are complete SOAP Responses.
System B in order to process the data it calls the integration platform to:
- Collect more data by calling one-to-many backend SOAP Services depending on whether they are required to execute. These services have a serial order, and are a mix of synchronous and asynchronous calls. There are 9 altogether.
- System B can only process data in the form of key value pairs. Therefore the integration platform had to aggregate and process the SOAP Responses from backend SOAP calls into key value pairs, as well as the SOAP Responses sent through from System A.
- System B requires the integration platform to send back a successful response even if an error occurred. There are two types of errors in this system;
- A soft stop error which means one of the calls to the backend services failed but continue processing.
- A hard stop error which means one of the calls to the backend services failed so stop processing and return the response.
Challenges
These requirements gave us some pretty interesting challenges;
- How to design the service so that it takes a JSON payload and calls multiple SOAP Services in the backend.
- Because System B can only process key value pairs, System A would pass values that contain potentially large SOAP Responses that are sent through to the integration platform for processing. Between the data coming from System A and System B, we had to account for sizes up to 1MB. Keep in mind while processing that payload is going to increase significantly depending on how much data you store in memory and if sent through persistent queues cannot exceed the maximum frame size or it shuts down the queue.
- How to manage and aggregate the responses depending on whether the status is a success, a soft stop or a hard stop.
Solutions
To address some of the challenges in the requirements we had to think about how we could design a system that would handle these requirements without overcomplicating things. Here are some of the designs we implemented and why;
Microservices
If you think about the requirements, there is a lot of mapping involved in an application like this. We are taking a single JSON payload and mapping it to potentially up to 9 service requests and doing a protocol change to SOAP, aggregating the responses and sending back the relevant data as JSON. There is also a lot of other tasks that it needs to do in order to process the SOAP Responses sent through from System A. This is too big for one service to manage, so we created microservices. The way we split them up is one application per WSDL, and each operation defined in the WSDL was a separate endpoint. So the macroservice would be responsible for mapping the data to each microservice (JSON->JSON), and each microservice would then do the protocol change from REST->SOAP and SOAP->REST. If the service supported caching we would cache the REST response so we don’t have to do any unnecessary mapping. Another reason why we wanted to encapsulate the protocol change in a microservice is because the backend SOAP Services themselves were passing large amounts of data with up to 3000 elements, so the mapping files themselves to do the protocol change were very large and often complex. The biggest reason for creating microservices is that they lend themselves better to reuse. Each microservice is essentially a wrapper to the SOAP Service exposing it as a REST interface.
Performance
How do you process large amounts of data and hit up to 9 endpoints in the backend over potentially several hops and do all this mapping and return within the SLA with high speed performance? By doing as much as you can concurrently and stream everything. So when we analyzed the data we looked at what we could process concurrently and what had to be processed serially. We had to look at what services are dependent on the execution of other services and ended up using a pattern which I called “buckets”. So we would execute serially and concurrently. Each bucket would have a serial order in which they are executed, and would contain several services that would be fired off concurrently. The buckets didn’t just contain calls to microservices, they contained all the additional processing too, so that we didn’t waste any time waiting for processing to finish where it was not necessary. Each bucket would take a copy of the payload, map the data it needs and execute the request, then take the response and map the data onto the original payload so that we could build the final response to be sent back to the calling service.
Payload Size
Passing around large amounts of data is not recommended in these type of transactional systems, and can lead to running low on server resources particularly if you have high traffic on a service. However, in this case the requirements meant that we had to pass around key value pairs with values containing extremely large SOAP payloads, sometimes with embedded PDFs. The biggest problem we started to notice with these large payloads is when sending the data through a persistent queue. If your client arbitrarily sends large frames that exceed the negotiated maximum frame size for the connection, you will be disconnected to protect the server to running out of memory. In order to start managing the payload size, we had to be really vigilant about what how we operate on that payload and keep it as lean as possible before sending it through to any operations that contain queues. If we operate on an object, say for example we convert an object from XML to JSON and we no longer need the XML representation of it, we would strip it out. We would only send through the absolute necessary data that we need to send through.
Service Execution
Each request would contain instructions on which services need to be called out to of the set of 9 services. In a concurrent model it is very difficult to fire off each process conditionally, so instead we execute all processes for each service and each process would then check if it needs to execute the service or do nothing. Also, each service would be aware of whether it was a soft stop or a hard stop and trigger the appropriate error handling steps.
Error Handling
In the case of a hard stop we can only stop executing the next serial step. If a process fails to execute a service that is called from a bucket, then each service in that bucket is already processing concurrently, so once that bucket is finished no other buckets will be processed. Errors need to be collected on the way and sent back to the calling service, but the service itself needs to send back a HTTP 200 response with instructions on what went wrong. From a monitoring perspective we still logged errors associated to error codes so that we can set up alerts through log management tools, but the way we report errors to the calling service would not be through a HTTP code but rather in the response format.
Threading
An application with the complexity of this magnitude is executing a lot of threads and therefore we needed to give considerable thought into managing threading profiles. Leaving the application on the default profiles is not enough. We devised a formula in which we used to apply:
- For the macroservice we matched the number of threads to the number of threads supported coming from the proxy application (API Gateway).
- For each bucket we took the number of threads * number of concurrent services.
- The microservices shared inbound HTTPS connector, so it was the number of threads * number of microservices with the shared connector.
- For the connector to the persistent queue it is the number of threads + (number of threads / 2) so that we maintain a buffer for when the queue disconnects periodically.
Various processing scenarios had different average times for processing, so some threads would be reused quicker than others. This allows for tuning down from the theoretical maximums whilst still enabling peak system performance. Thorough testing and analysis of the JVM will provide the insights required to make adjustments of that nature.
Production
The application logs every step with wire logging details. This was essential for troubleshooting mapping problems between the flat structure of key/value pairs and the multi-layered SOAP structures. The SOAP services were undocumented, so extensive wire logging was also key to working through how business functionality was to be accessed through the SOAP services. Due to the large payloads of information both from the source system (only a subset of the source request was required by the SOAP based systems) and the large XML structures for the SOAP services, informational logging under load testing and production was turned off. This meant only warnings and errors would be logged in load testing and production. Whilst warnings and errors provided information on problems, they did not contain contextual information around the problem. This was provided by the informational logging, which was now to be turned off for production and load testing. Customer support staff identified that they required the original request and response in order to troubleshoot in production, as well as error notifications for when SOAP services were operating under parameterized time thresholds. We used an envelope interceptor for both tasks. Envelope interceptors, with parameterized thresholds injected using the Spring framework, wrap each micro service flow. The interceptors provide log alerts when SOAP services slow beyond varying thresholds (the SOAP services are unable to monitor themselves for slow service or wire log requests and responses). A similar technique was used to record and log the request if an error response was generated by the system.
Conclusion
These are some of the high level design solutions we used to approach solving the requirements, from a low level we had many other challenges. The integration platform we used was Mule ESB and some of the native capabilities of the platform were a huge plus in executing a solution such as this. In particular, scatter gather for concurrency, dataweave for the mapping and interceptors for the service monitoring.